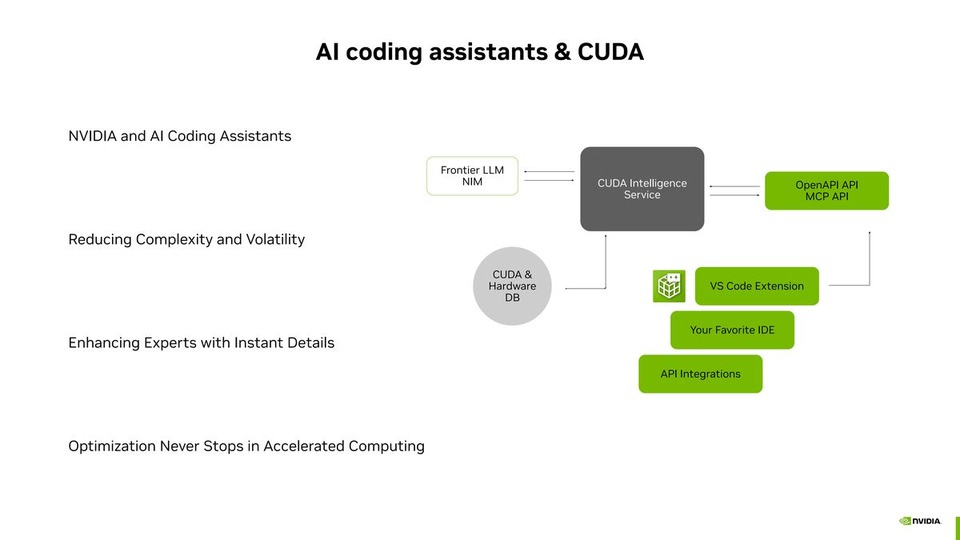
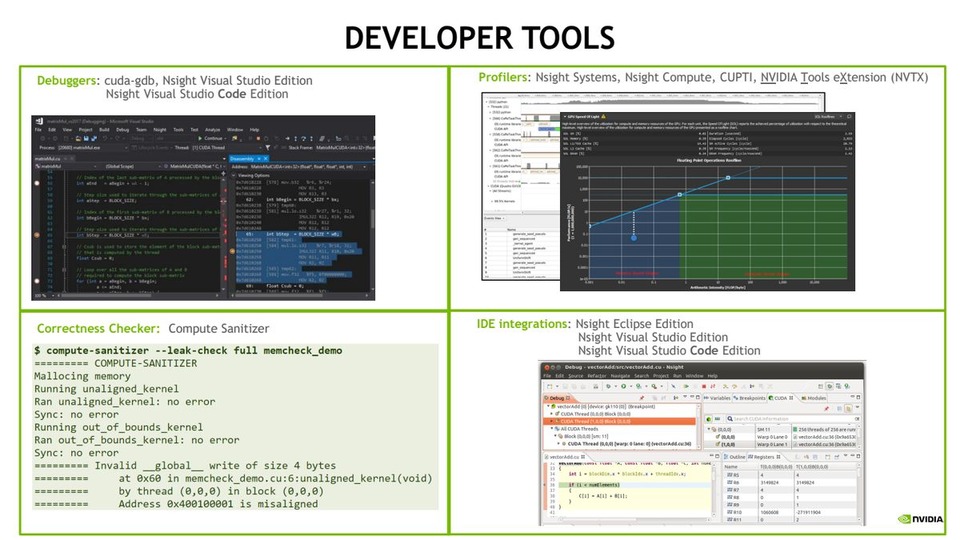
LLM
-
 Best practice of Blackwell GPU deployment in the Chinese market
Best practice of Blackwell GPU deployment in the Chinese market何平, NVIDIA TensorRT团队 高级工程师 张一林, NVIDIA GPU加速计算专家团队 高级工程师 AI Open Day 20251107
-
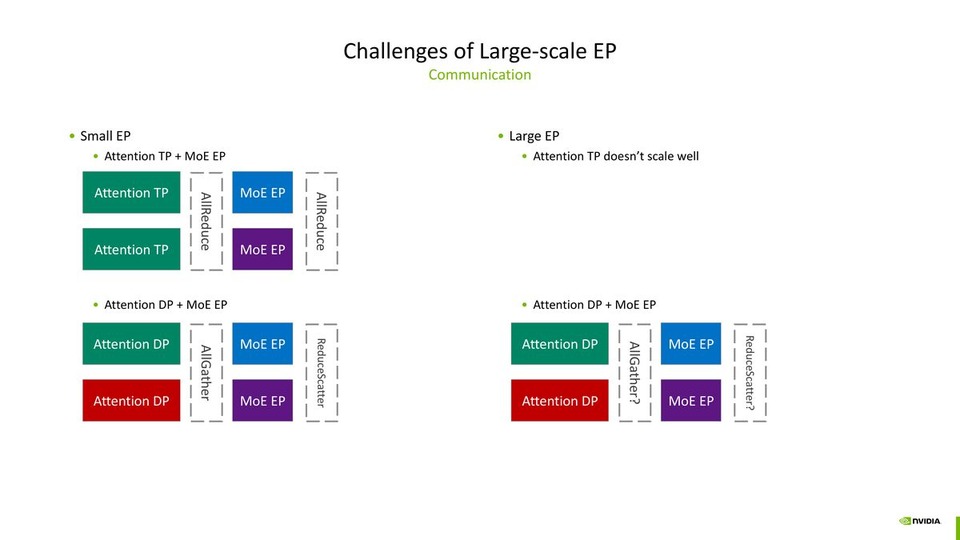 TensorRT-LLM Large-scale Expert Parallelism Optimizations
TensorRT-LLM Large-scale Expert Parallelism OptimizationsEnwei Zhu (朱恩伟), NVIDIA 加速计算专家团队 高级工程师 Jinyang Yuan (袁劲飏), NVIDIA 加速计算专家团队 高级工程师
-
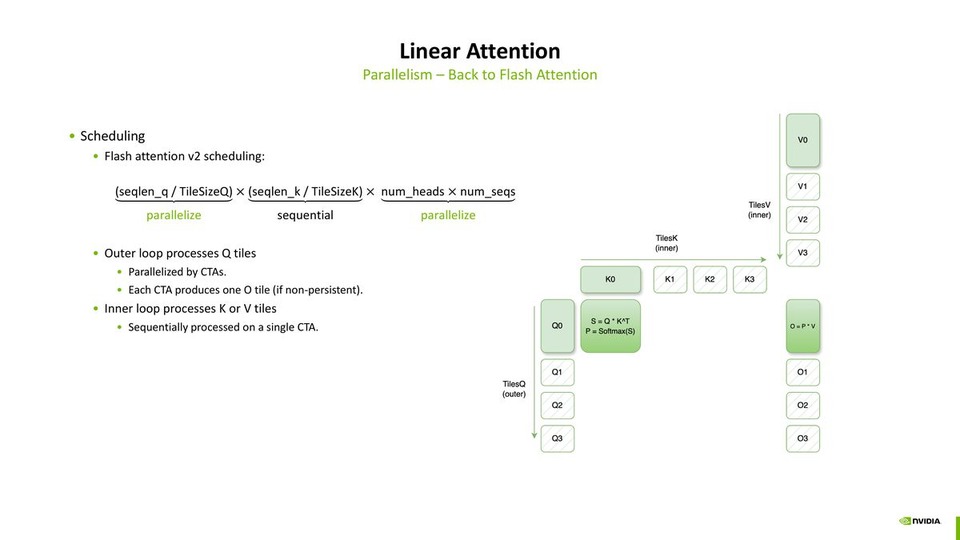 Linear Attention
Linear Attention韩广云,NVIDIA GPU 加速计算专家团队 高级工程师 | AI Open Day/2025-11-07
-
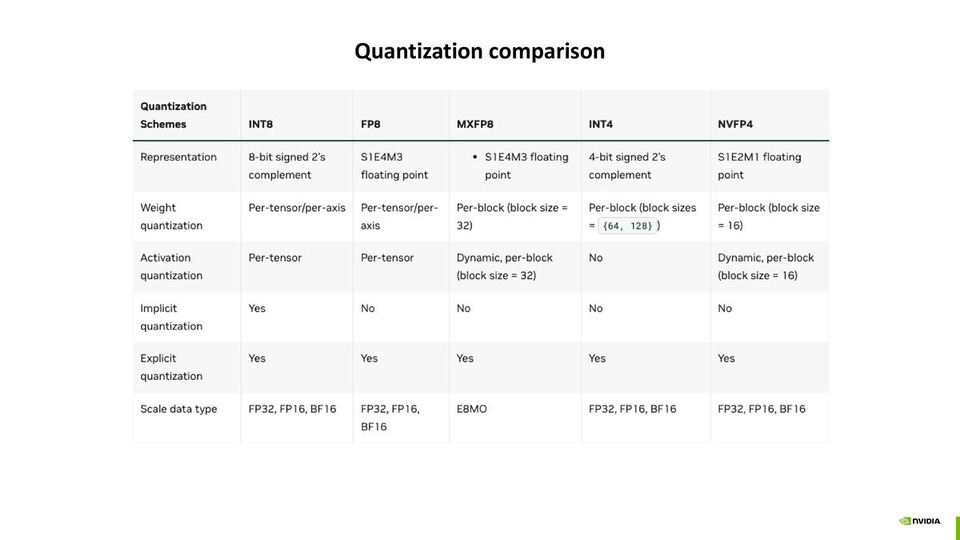 A Practical Guide to Deploying NVFP4 for Efficient Inference on Blackwell GPUs
A Practical Guide to Deploying NVFP4 for Efficient Inference on Blackwell GPUs薛博阳, NVIDIA 加速计算专家团队 高级工程师 2025/11/07
-
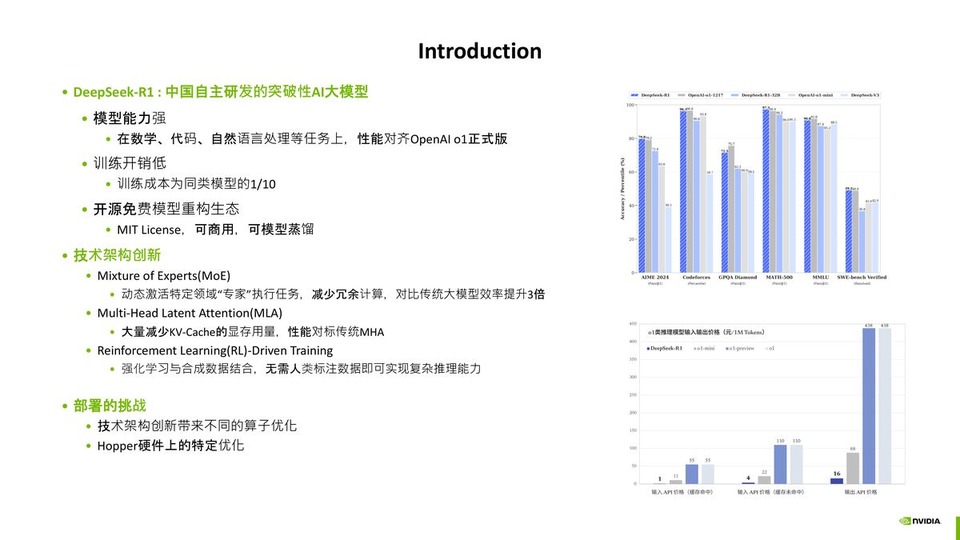 TensorRT-LLM驱动DeepSeek性能极限-协同腾讯联合优化实践
TensorRT-LLM驱动DeepSeek性能极限-协同腾讯联合优化实践Raccoon Liu : 腾讯大模型推理负责人 朱文熙 : 腾讯开悟平台研发负责人 王猛 : NVIDIA 高级加速计算专家
-
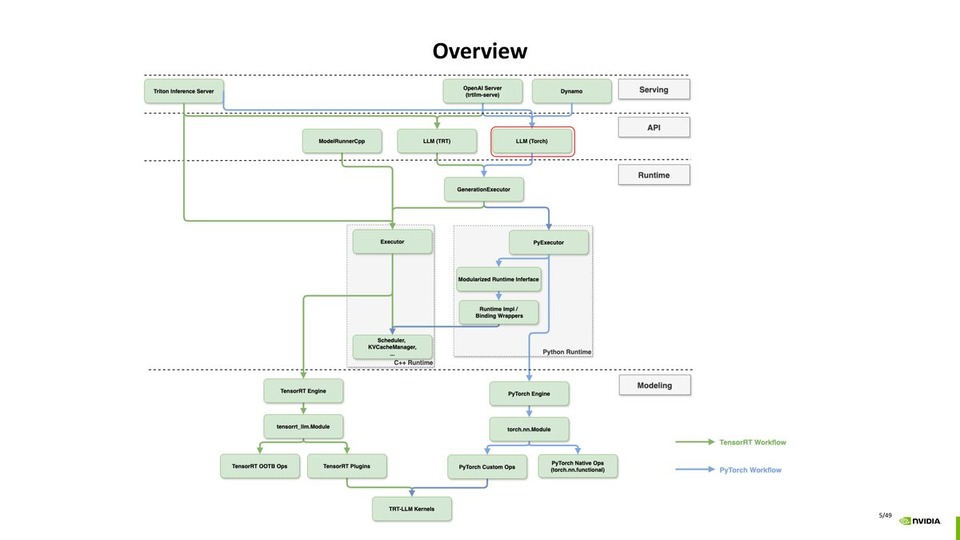 TensorRT-LLM × PyTorch: A New Development Paradigm for High-Performance LLM Inference
TensorRT-LLM × PyTorch: A New Development Paradigm for High-Performance LLM Inference更多示例和参数: 更多带有附加参数的示例可在 examples/pytorch/quickstart_advanced.py 中找到。
-
 TensorRT-LLM
TensorRT-LLMTensorRT LLM 旨在帮助用户在 NVIDIA AI 平台上获得大型语言模型(LLM)推理部署的最佳性能。
-
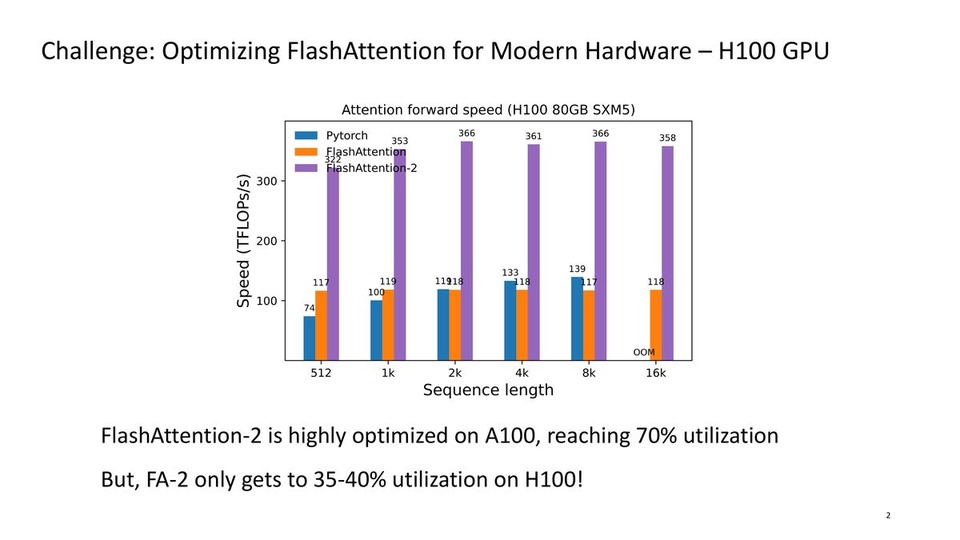 FlashAttention-3: Fast and Accurate Attention with Asynchrony and Low-precision
FlashAttention-3: Fast and Accurate Attention with Asynchrony and Low-precisionTri Dao¹ and Jay Shah² ¹ Together AI / Princeton University, tri@tridao.me ² ...
-
 Megatron Core MoE Updates - 2025 H2
Megatron Core MoE Updates - 2025 H2颜子杰, 陈楷文 | NVIDIA GPU加速计算专家团队 | Nov 07, 2025
-
 Distributed Implementation of Muon and Emerging Optimizers in Megatron-Core
Distributed Implementation of Muon and Emerging Optimizers in Megatron-Core傅德禹, NVIDIA GPU 加速计算专家团队 | Al Open Day | Nov 07, 2025
-
 Best Practice of MLA Kernel Optimization on Blackwell
Best Practice of MLA Kernel Optimization on Blackwell王泽宇, NVIDIA GPU加速计算专家团队 高级工程师 | November 7, 2025
-
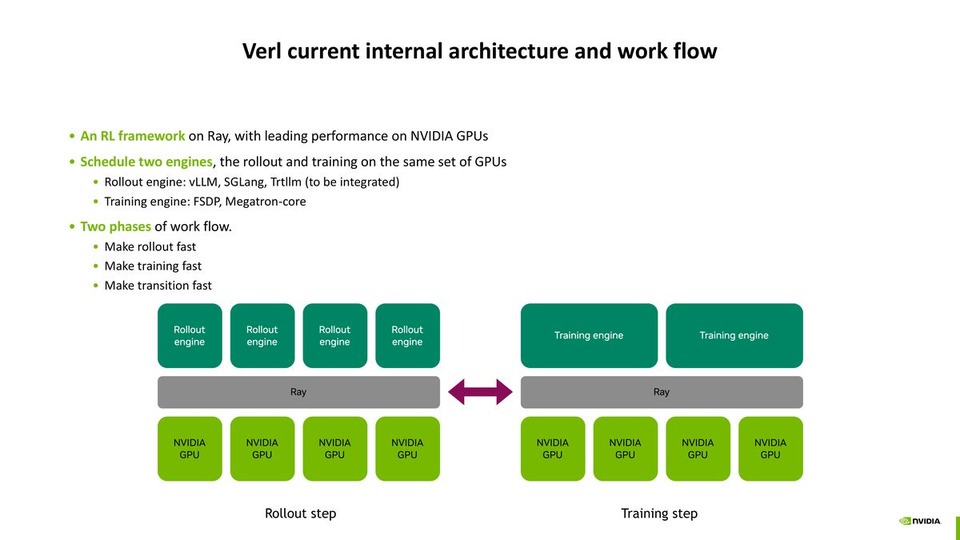 Best Practices of Reinforcement Learning with verl
Best Practices of Reinforcement Learning with verlLiwei Ma, Yan Bai, DevTech China | NVIDIA AI Open Day, Nov. 7th, 2025
-
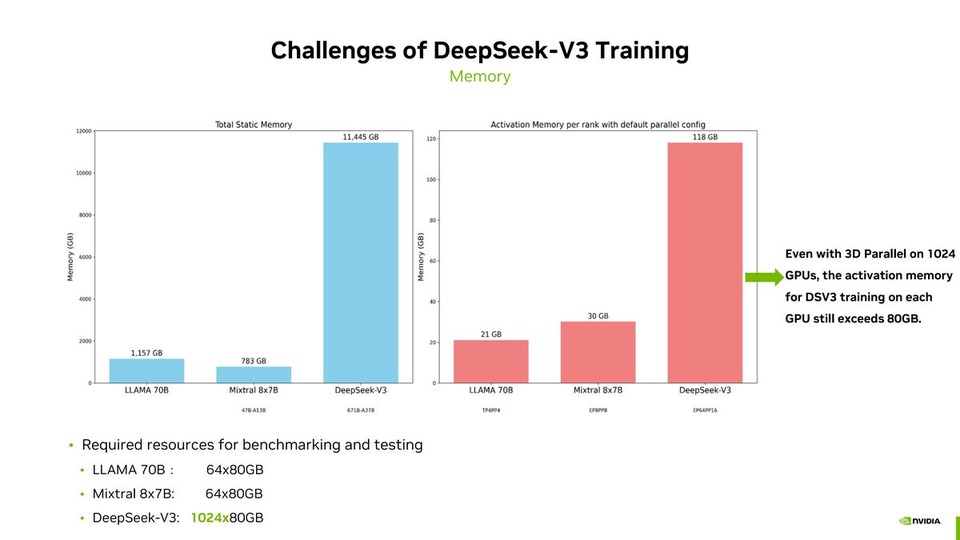
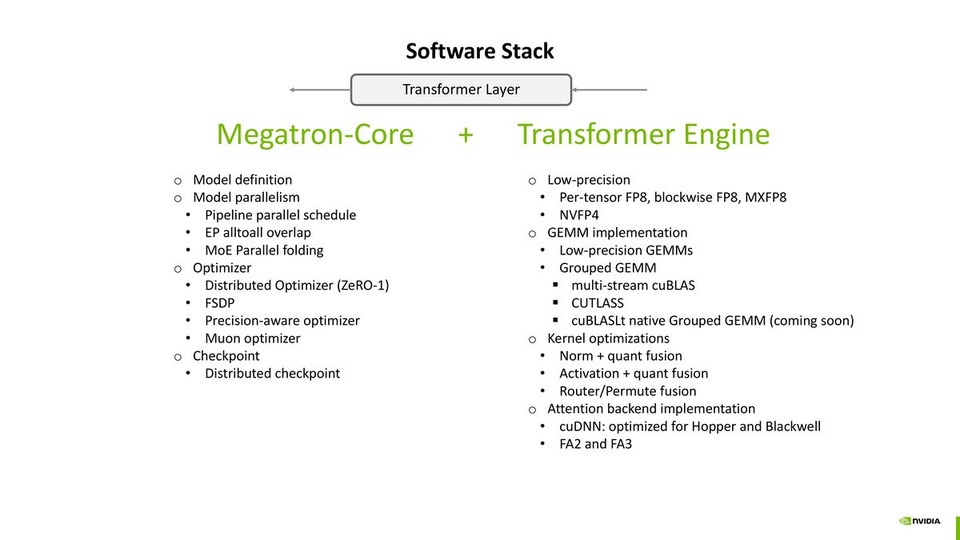 DeepSeek-V3 Pre-training Optimization on Grace Blackwell
DeepSeek-V3 Pre-training Optimization on Grace Blackwell姚鑫 | NVIDIA GPU加速计算专家团队 高级工程师 | NVIDIA AI Open Day, Nov. 7th, 2025
-
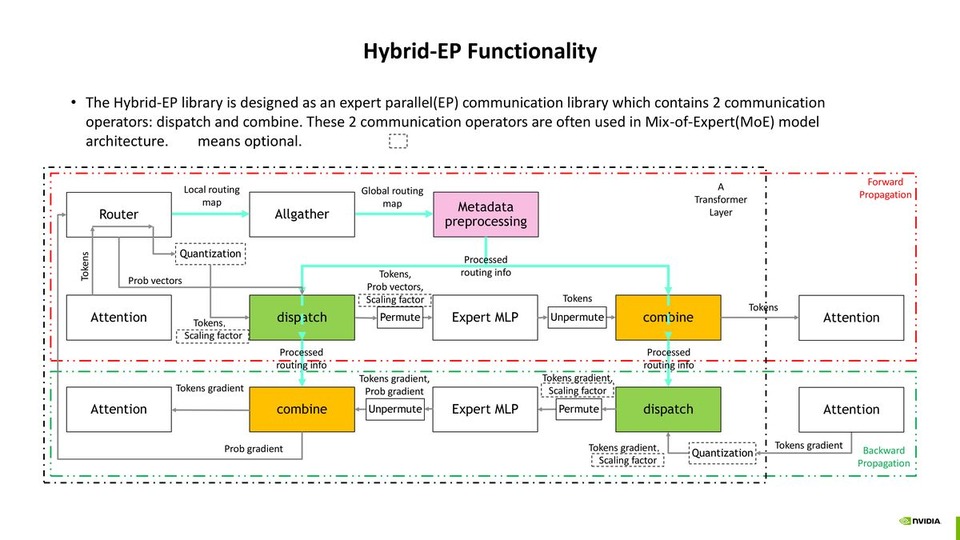 Hybrid-EP: An Efficient MoE Communication Implementation
Hybrid-EP: An Efficient MoE Communication Implementation郁凡, 刘童, NVIDIA GPU加速计算专家团队, 高级工程师 | NVIDIA AI Open Day, Nov. 7th, 2025
-
 MCore MoE in 2025 - DeepSeek-V3 and Beyond
MCore MoE in 2025 - DeepSeek-V3 and BeyondZijie Yan and Hongbin Liu NVIDIA
-
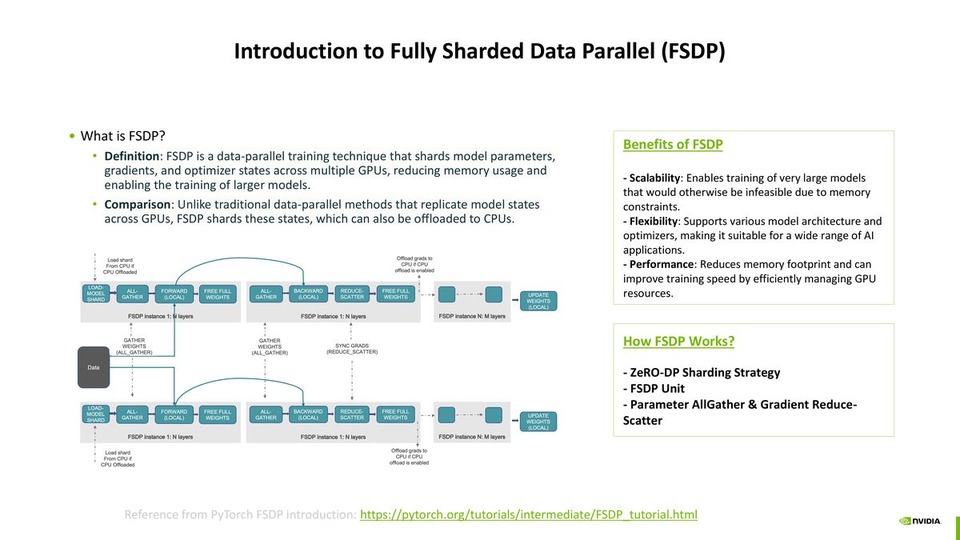 Megatron-Core Custom FSDP
Megatron-Core Custom FSDP全分片数据并行(FSDP)简介 - FSDP 工作原理:ZeRO-DP 分片策略 - FSDP 工作原理:FSDP 单元 ...
-
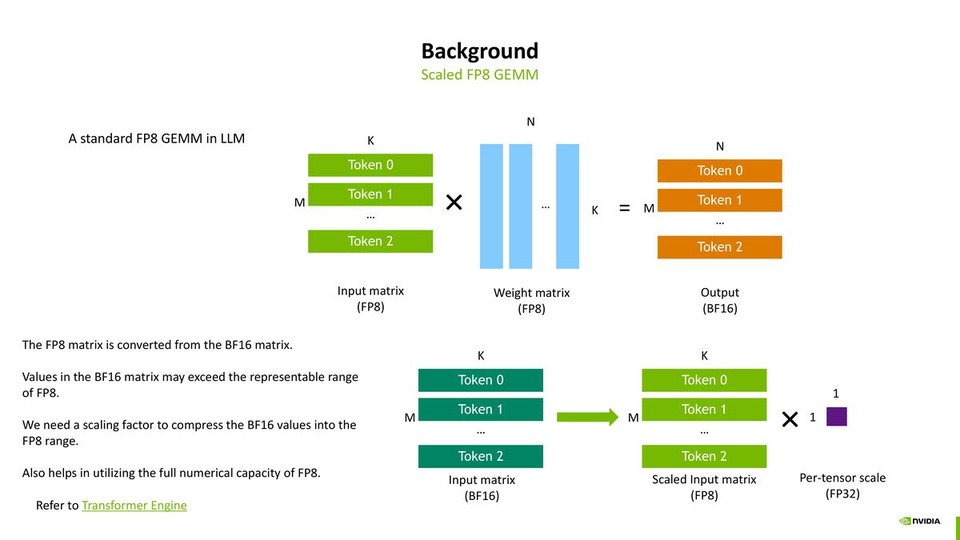
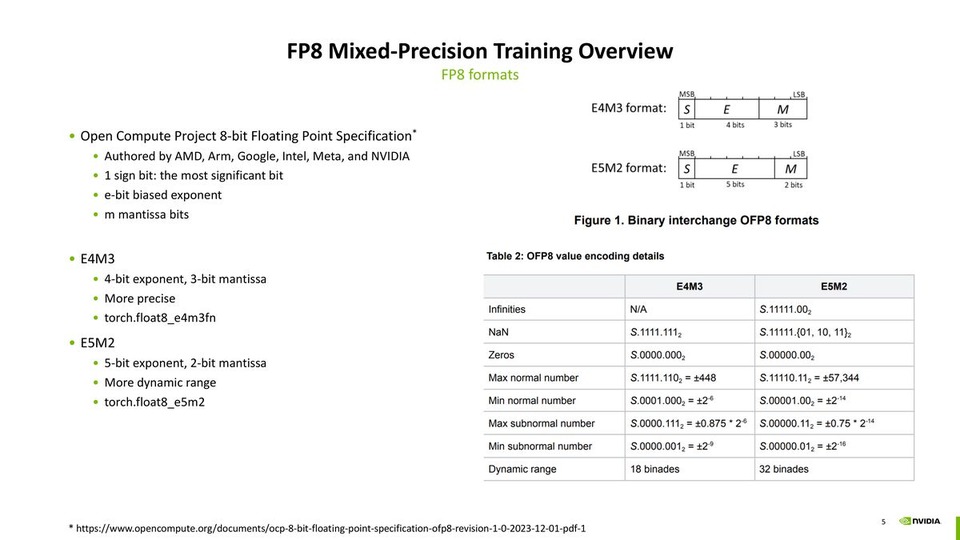 FP8 Training Recipes, Performance and Convergence
FP8 Training Recipes, Performance and ConvergenceXin Yao, DevTech | AI Open Day/May 30, 2025
-
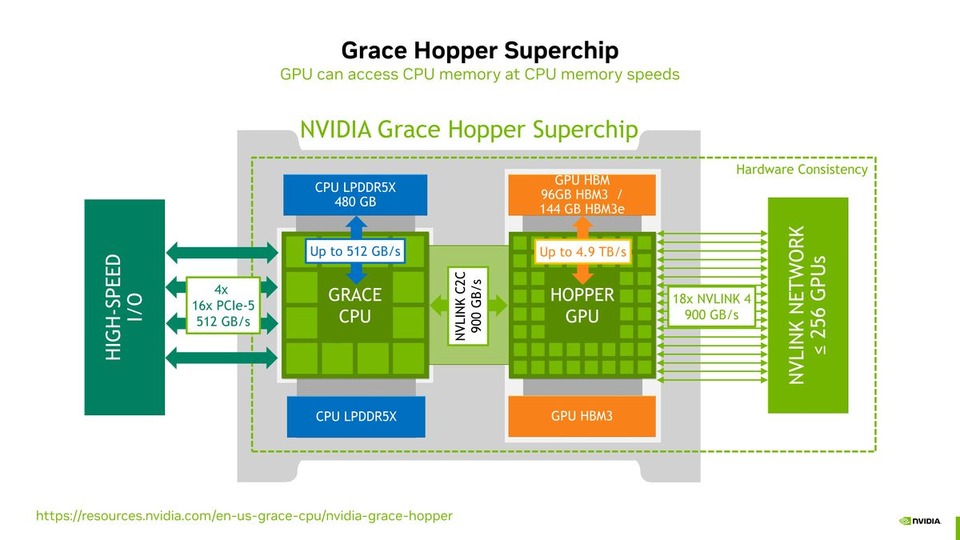
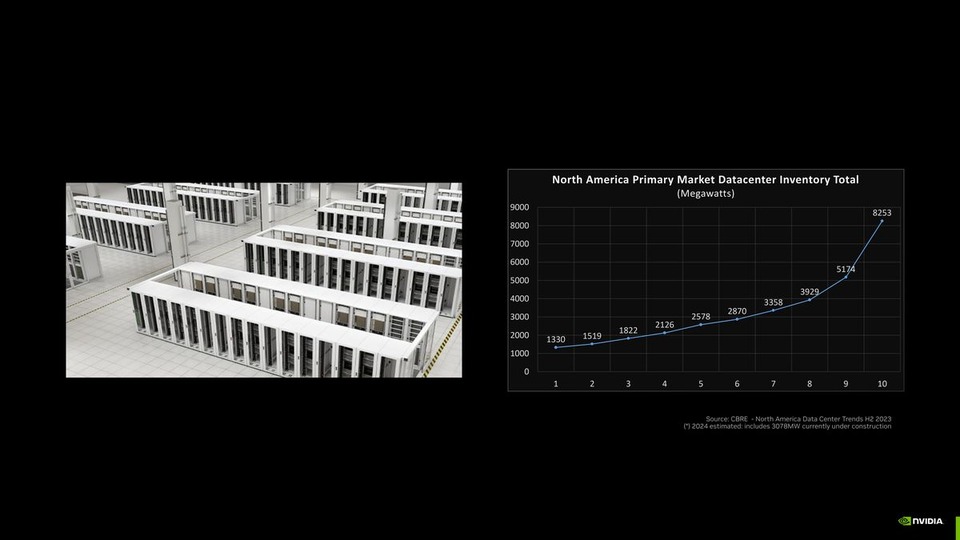
 Profiling Large Language Model Trainings on the Grace Hopper Superchip using Nsight Systems
Profiling Large Language Model Trainings on the Grace Hopper Superchip using Nsight SystemsKarin Sevegnani, Senior Solutions Architect, NVAITC UK | GTC2025 Giuseppe Fia...


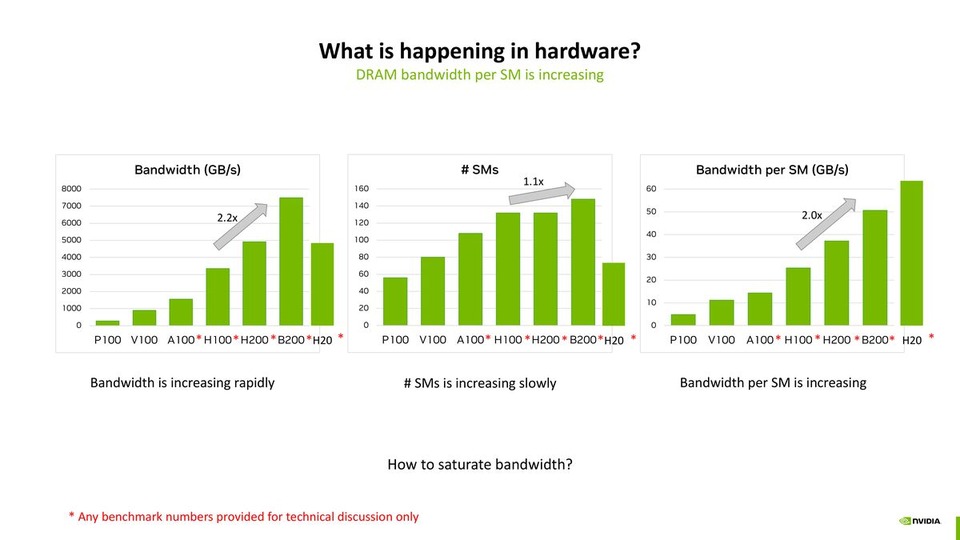
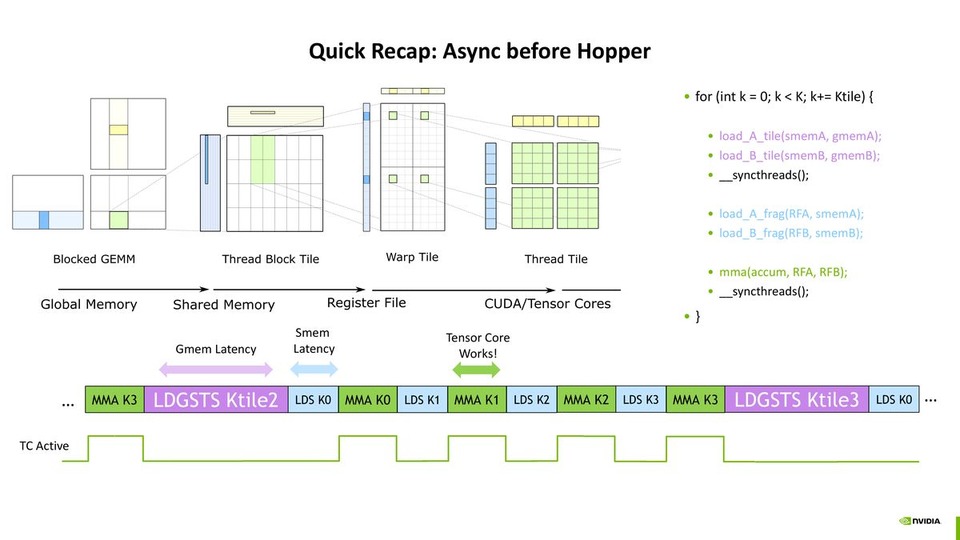
![thumbnail of CUDA Techniques to Maximize Compute and Instruction Throughput [S72685]](/papercache/assets/data/01b087cb.jpg)
![thumbnail of CUDA Techniques to Maximize Memory Bandwidth and Hide Latency [S72683]](/papercache/assets/data/188a47b3.jpg)
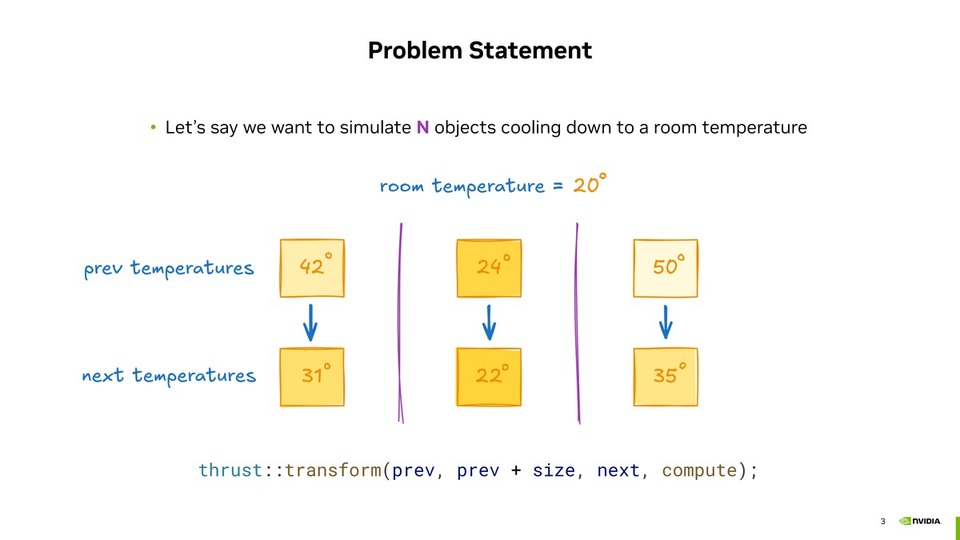


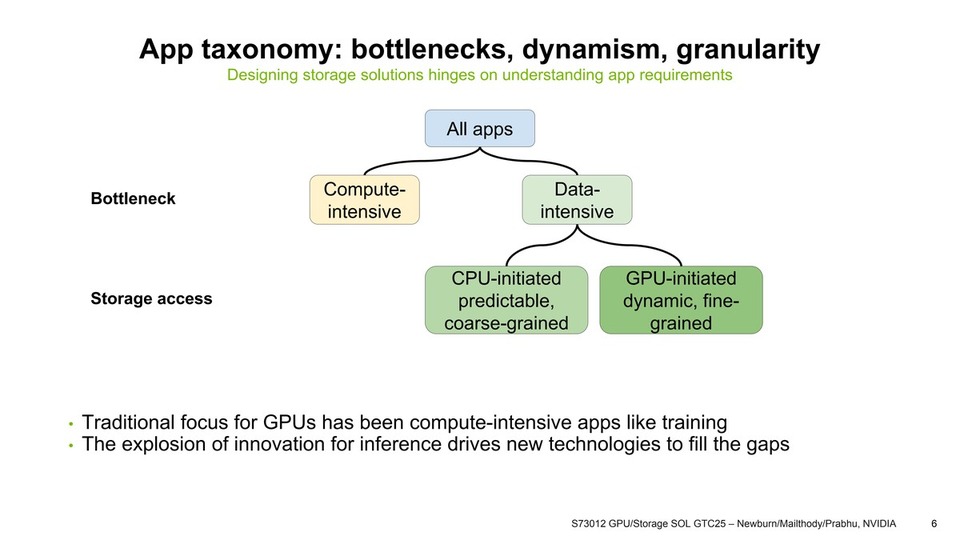
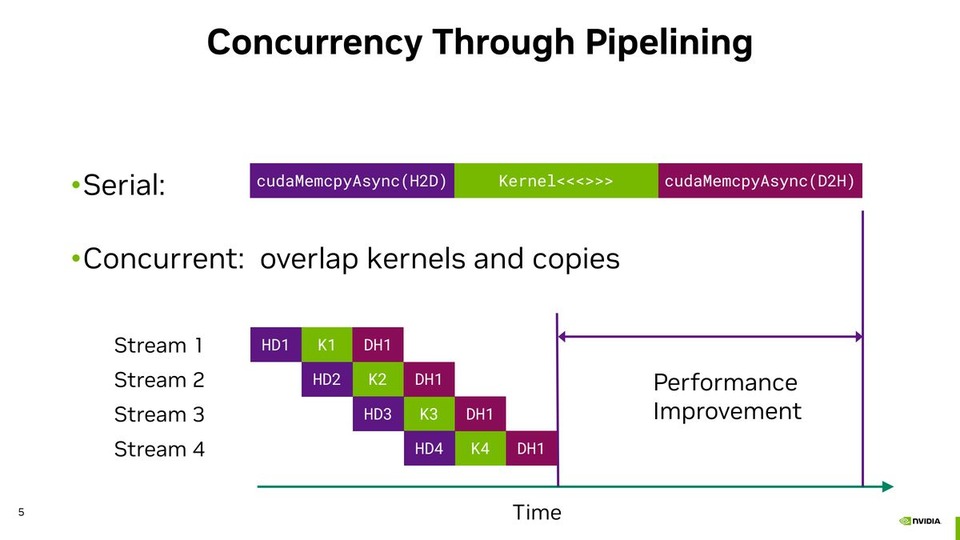
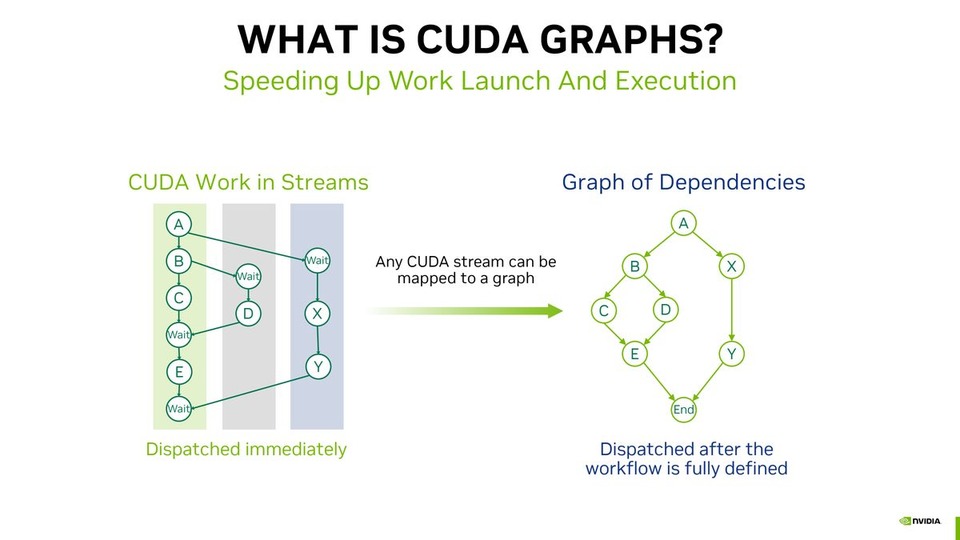
![thumbnail of Performance Optimization Tutorial, Part 3 [S72686]: CUDA Techniques to Maximize Concurrency and System Utilization](/papercache/assets/data/aab1851f.jpg)



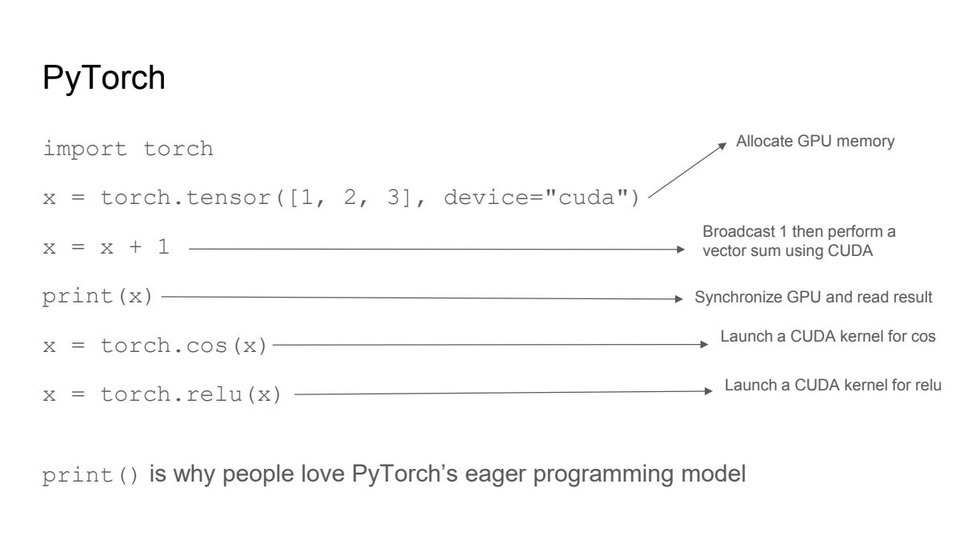


![thumbnail of Advanced Performance Optimization in CUDA [S62192]](/papercache/assets/data/e0458e86.jpg)